


Detailed Explanation of Distributed ID
Introduction to Distributed ID
What is an ID?
In daily development, we need to use ID to uniquely represent all kinds of data in the system, such as user ID corresponding to and only corresponding to one person, commodity ID corresponding to and only corresponding to one commodity, and order ID corresponding to and only corresponding to one order.
We also have various IDs in real life, such as ID ID corresponding to and only corresponding to one person, address ID corresponding to and only corresponding to
Simply put, ** The ID is the unique identification of the data **.
What is a distributed ID?
Distributed ID is the ID under distributed system. Distributed ID does not exist in real life, and belongs to a concept in computer system.
Let me give a simple example of sub-database and sub-table.
A project of our company uses stand-alone MySQL. However, unexpectedly, one month after the project went online, with the increasing number of users, the data volume of the whole system will become larger and larger. Stand-alone MySQL has no way to support, need to sub-library sub-table (recommended Sharding-JDBC).
After the sub-database, the data is spread all over the databases on different servers, and the self-increasing primary key of the database can no longer meet the unique primary key generated. ** How do we generate globally unique primary keys for different data nodes? **
This is when you need to generate ** Distributed ID **.
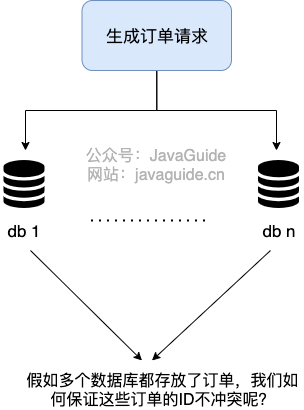
What requirements do distributed IDs need to meet?
As an indispensable part of distributed system, distributed ID is used in many places.
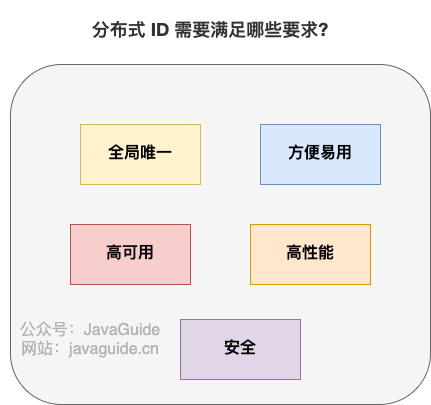
A basic distributed ID needs to meet the following requirements:
- ** Global uniqueness **: The global uniqueness of the ID must be the first thing to satisfy!
- ** High performance **: Distributed IDs are generated faster and consume less local resources.
- ** High availability **: Services that generate distributed IDs are guaranteed infinitely close to 100% availability.
- ** Convenient and easy to use **: Ready to use, easy to use, quick access!
In addition to these, a better distributed ID should also guarantee:
- ** Safety **: The ID does not contain sensitive information.
- ** Ordered increment **: If you want to store IDs in the database, the order of IDs can improve the database write speed. Moreover, most of the time, we are likely to sort directly by ID.
- ** Have specific business meanings **: If the generated ID has specific business implications, it can make locating problems and development more transparent (you can determine which business it is by ID).
- ** Independent deployment **: That is, the distributed system has a separate numberer service dedicated to generating distributed IDs. In this way, the service that generates ID can be decoupled from the business-related service. However, this also brings the problem of increasing network call consumption. Generally speaking, if there are many scenarios where distributed ID is needed, it is necessary to deploy the numberer service independently.
Common Solutions for Distributed ID
Database
Database primary key self-increment
This method is relatively simple and straightforward, that is, the unique ID is generated by the self-increasing primary key of relational database.
Take MySQL as an example, we can do it in the following ways.
** 1. Create a database table. **
CREATE TABLE `sequence_id` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`stub` char(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
The stub field is meaningless and is just a placeholder for us to insert or modify data. Also, a unique index is created for the stub field to ensure its uniqueness.
** 2. Insert data with replace into. **
BEGIN;
REPLACE INTO sequence_id (stub) VALUES ('stub');
SELECT LAST_INSERT_ID();
COMMIT;
Insert data Here, instead of using insert into, we use replace into to insert data, as follows:
1)Step 1: Try to insert data into the table.
2)Step 2: If the primary key or unique index field fails to insert due to duplicate data errors, delete the conflicting row with duplicate key values from the table, and then try to insert the data into the table again.
The advantages and disadvantages of this method are also obvious:
- ** Advantages **: It is simple to implement, with orderly increment of ID and small storage consumption
- ** Disadvantages **: The concurrency supported is not large, and there is a single database problem (which can be solved by using database cluster, but the complexity is increased). ID has no specific business meaning, and security problems (such as calculating the daily order quantity according to the increasing law of order ID, trade secrets! ), accessing the database once every time you get the ID (which increases the pressure on the database and slows down the acquisition speed)
Database number segment schema
Database primary key self-increase this mode, every time you get ID, you have to visit the database. When the ID demand is relatively large, it is definitely not possible.
If we can get it in batches and then exist in memory, when we need it, it is comfortable to take it directly from memory! This is what we call ** Generate distributed ID based on the number segment schema of database. **
The number segment mode of database is also a mainstream distributed ID generation mode at present. Tinyid, like Didi Open Source, is based on this way. However, TinyId uses double-numbered segment caching and adds multi-db support to further optimize.
Take MySQL as an example, we can do it in the following ways.
** 1. Create a database table. **
CREATE TABLE `sequence_id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`step` int(10) NOT NULL COMMENT '号段的长度',
`version` int(20) NOT NULL COMMENT '版本号',
`biz_type` int(20) NOT NULL COMMENT '业务类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
The current_max_id fields and the step fields are used primarily to obtain the batch id, which is current_max_id ~ current_max_id+step.
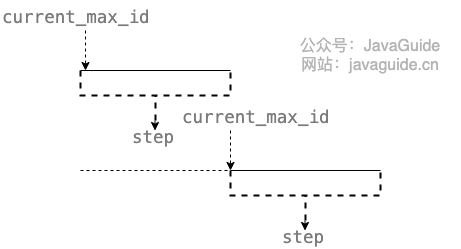
The version field is primarily used to address concurrency (optimistic locking), and the biz_type field is primarily used to indicate the type of business.
** 2. Insert a row of data first. **
INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
VALUES
(1, 0, 100, 0, 101);
** 3. Get the batch unique ID under the specified service by SELECT **
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
Results:
id current_max_id step version biz_type
1 0 100 0 101
** 4. If it is not enough, re-SELECT after updating. **
UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
Results:
id current_max_id step version biz_type
1 100 100 1 101
Compared with the way the database primary key is self-incremented, ** The number segment mode of the database has less access to the database and less pressure on the database. **
In addition, in order to avoid single-point problems, you can improve usability by using master-slave mode.
** advantages and disadvantages of database number segment schema: **
- ** Advantages **: ID is incremented in order, and the storage consumption is small
- ** Disadvantages **: There are single-point database problems (which can be solved by database cluster, but the complexity is increased), ID has no specific business meaning, and security problems (such as calculating the daily order quantity according to the increasing law of order ID, trade secrets!)
NoSQL

In general, NoSQL schemes use Redis more. We can sequentially increment id atoms through Redis' incr command.
127.0.0.1:6379> set sequence_id_biz_type 1
OK
127.0.0.1:6379> incr sequence_id_biz_type
(integer) 2
127.0.0.1:6379> get sequence_id_biz_type
"2"
To improve availability and concurrency, we can use the Redis Cluster. Redis Cluster is the official Redis Cluster solution (version 3.0 +).
In addition to the Redis Cluster, you can also use the open source Redis Cluster solution Codis (recommended for large-scale clusters such as hundreds of nodes).
In addition to high availability and concurrency, we know that Redis is memory-based, and we need to persist data to avoid data loss after machine restart or machine failure. Redis supports two different ways of persistence: ** Snapshot (RDB) ** and ** append-only file (AOF) **. Also, Redis 4.0 begins to support ** Mixed Persistence of RDB and AOF ** (off by default and can be turned on through the configuration item aof-use-rdb-preamble).
As for Redis persistence, I will not introduce too much here. For those who don't know this part, you can look at JavaGuide Summary of Redis Knowledge Points.
** advantages and disadvantages of the Redis scenario: **
- ** Advantages **: The performance is good and the generated ID is incremented in an orderly manner
- ** Disadvantages **: Similar disadvantages to database primary key self-increment scheme
Besides Redis, MongoDB ObjectId is often used as a distributed ID solution.

MongoDB ObjectId requires a total of 12 bytes of storage:
- 0 ~ 3: Time stamp
- 3 ~ 6: Represents the machine ID
- 7 ~ 8: Machine process ID
- 9 ~ 11: Self-increment
** advantages and disadvantages of MongoDB scheme: **
- ** Advantages **: The performance is good and the generated ID is incremented in an orderly manner
- ** Disadvantages **: Duplicate IDs need to be resolved (which may result in duplicate IDs when the machine time is wrong), security issues (ID generation is regular)
Algorithm
UID
UUID is an abbreviation for Universally Unique Identifier. The UUID contains 32 hexadecimal digits (8-4-4-4-12).
The JDK provides a ready-made way to generate a UUID, just one line of code.
//输出示例:cb4a9ede-fa5e-4585-b9bb-d60bce986eaa
UUID.randomUUID()
The example of a UUID in RFC 4122 looks like this:
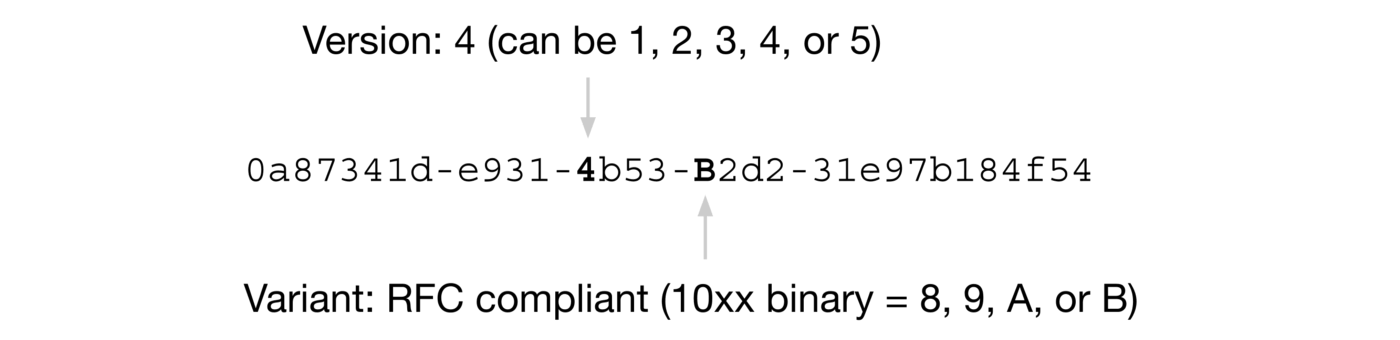
Let's focus on this Version here. Different versions have different UUID generation rules.
The corresponding meanings of five different Version values (refer to Wikipedia's introduction to UUID):
- ** Version 1 **: UUID is generated based on time and node ID (usually MAC address);
- ** Version 2 **: UUID is generated based on identifier (usually group or user ID), time, and node ID;
- ** Version 3, Version 5 **: Version 5-Deterministic UUIDs are generated by hashing namespace identifiers and names;
- ** Version 4 **: UUID is generated using 随机性 or 伪随机性.
The following is an example of a UUID generated under Version 1:

The version of the UUID generated by the randomUUID() method of UUID in the JDK defaults to 4.
UUID uuid = UUID.randomUUID();
int version = uuid.version();// 4
In addition, Variant also has four different values, which correspond to different meanings. I won't introduce it here. It seems that I don't need much attention at ordinary times.
When you need to use it, just look at Wikipedia's introduction to UUID Variant.
From the above introduction, it can be seen that UUID can guarantee uniqueness, because its generation rules include MAC address, timestamp, Namespace, random or pseudo-random number, time series and other elements, and UUID generated by computer based on these rules will definitely not be repeated.
Although UUID can be globally unique, we rarely use it.
For example, it is very inappropriate to use UUID as the primary key of MySQL database:
- The database primary key should be as short as possible, while UUID consumes a large storage space (32 strings, 128 bits).
- UUID is out of order. Under InnoDB engine, the disorder of database primary key will seriously affect database performance.
Finally, let's briefly analyze ** Advantages and disadvantages of UUID ** (which may be asked during the interview!) :
- ** Advantages **: The build is fast and easy to use
- ** Disadvantages **: Large storage consumption (32 strings, 128 bits), unsafe (the algorithm of generating UUID based on MAC address will cause MAC address leakage), disordered (non-self-increasing), no specific business meaning, and need to solve the problem of duplicate ID (when the machine time is wrong, it may lead to duplicate ID)
Snowflake (Snowflake algorithm)
Snowflake is Twitter's open source distributed ID generation algorithm. Snowflake consists of 64-bit binary numbers, which are divided into several parts, and each part stores data with specific meanings:
- ** The 0 th bit **: Sign bit (identifying plus or minus), always 0, no use, don't worry about it.
- ** Position 1 ~ 41 **: A total of 41 bits, used to denote a timestamp, in milliseconds, that lasts 2 ^ 41 milliseconds (approximately 69 years)
- ** Bits 42 ~ 52 **: There are 10 digits in total. Generally speaking, the first 5 digits represent the machine room ID, and the last 5 digits represent the machine ID (which can be adjusted according to the actual situation in actual projects). In this way, you can distinguish the nodes of different clusters/computer rooms.
- ** Bits 53 ~ 64 **: A total of 12 bits, used to denote the serial number. The serial number is self-increment, which represents the maximum number of IDs that a single machine can generate per millisecond (2 ^ 12 = 4096), which means that a single machine can generate up to 4096 unique IDs per millisecond.

If you want to use the Snowflake algorithm, you generally don't need to recreate the wheel yourself. There are many open source implementations based on Snowflake algorithm, such as Leaf of Meituan and UidGenerator of Baidu, and these open source implementations optimize the original Snowflake algorithm.
In addition, in actual projects, we will generally transform the Snowflake algorithm, and the most common one is to add business type information to the ID generated by Snowflake algorithm.
Let's look at the advantages and disadvantages of Snowflake algorithm:
- ** Advantages **: The generation speed is relatively fast, and the generated ID increases in an orderly manner, which is relatively flexible (the Snowflake algorithm can be simply modified, such as adding business ID)
- ** Disadvantages **: Duplicate IDs need to be resolved (time-dependent, which can result in duplicate IDs if the machine time is wrong).
Open source framework
UidGenerator (Baidu)
Urine generator is a unique ID generator based on Snowflake, which is open source by Baidu.
However, UidGenerator has improved on Snowflake, and the unique ID generated is composed as follows.

As you can see, the composition of the unique ID generated by the original Snowflake algorithm is different. Moreover, we can customize the above parameters.
The UidGenerator official documentation describes the following:

Since 18 years later, UidGenerator has been basically no longer maintained, and I will not introduce it too much here. For those who want to know more, you can see Official introduction of UidGenerator.
Leaf (US Mission)
** Leaf ** is an open source distributed ID solution of Meituan. The name of this project Leaf originated from the words of German philosopher and mathematician Leibniz: "There are no two identical leaves in the world" (There are no two identical leaves in the world). This name is really good, and it tastes like a literary youth!
Leaf provides two modes, ** Segment mode ** and ** Snowflake (Snowflake algorithm) **, to generate distributed IDs. Moreover, it supports double-numbered segments and solves the clock callback problem of snowflake ID system. However, the solution to the clock problem needs to be weakly dependent on Zookeeper.
Leaf was born mainly to solve the problems of various and unreliable methods for generating distributed IDs in various business lines of Meituan.
Leaf improves on the original number segment mode, for example, it adds double-numbered segments here to avoid blocking the thread requesting to obtain ID when obtaining the number segment. To put it simply, before I finished one number segment, I took the initiative to get the next number segment in advance (the picture comes from the official article of Meituan: [Leaf-Meituan Review Distributed ID Generation System]).

According to README introduction of the project, based on 4C8G VM, it is called by RPC mode of the company, and the QPS pressure measurement result is nearly 5w/s, TP999 1ms.
Tinyid (Didi)
Tinyid is a unique ID generator based on database number segment schema.
The principle of database number segment mode has been introduced above. ** What are the highlights of Tinyid? **
To figure this out, let's first look at a simple schema based on the database number segment schema. (Image from Tinyid's official wiki: Introduction to Tinyid Principle)
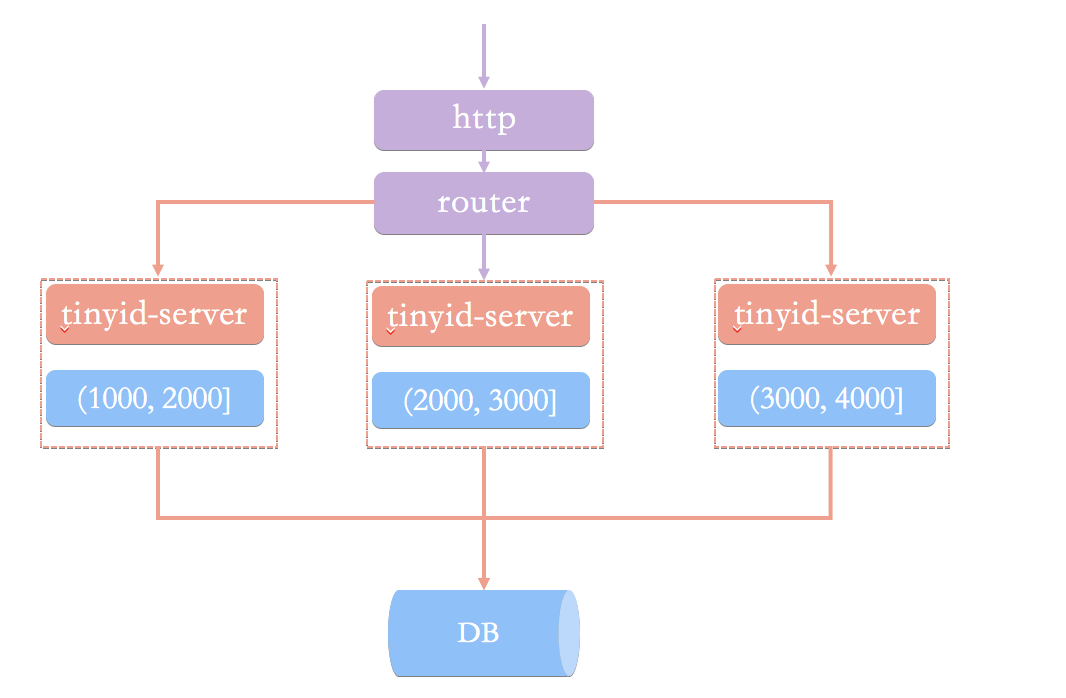
In this architecture pattern, we request a unique ID from the numberer service via an HTTP request. The load balancing router sends our request to one of the tinyid-servers.
What's wrong with this scheme? In my opinion (Tinyid's official wiki is also introduced), it is mainly caused by the following two questions:
- In the case of obtaining a new number segment, the program is slow to obtain a unique ID.
- It is necessary to ensure high availability of DB, which is troublesome and resource-consuming.
In addition, HTTP calls also have network overhead.
The principle of Tinyid is relatively simple, and its architecture is shown in the following figure:

Compared with the simple architecture scheme based on the database number segment schema, Tinyid scheme mainly makes the following optimizations:
- ** Double segment cache **: In order to avoid the slow speed of obtaining unique ID in the case of obtaining new number segment. When the number segment in Tinyid is used to a certain extent, it will load the next number segment asynchronously to ensure that there are always available number segments in memory.
- ** Adding multi-db support **: Multiple DBs are supported, and each DB can generate a unique ID, which improves availability.
- ** Add tinyid-client **: Pure local operation, no HTTP request consumption, significant performance and availability improvements.
The advantages and disadvantages of Tinyid will not be analyzed here, but can be known by combining the advantages and disadvantages of database number segment mode and the principle of Tinyid.
Summarize
Through this article, I have basically summarized the most common distributed ID generation schemes.
In addition to the methods described above, middleware like ZooKeeper can also help us generate unique IDs. ** Without silver bullets, we must choose the most suitable scheme according to the actual project. **
评论区